
티스토리 뷰
scrapy 튜토리얼을 끝냈으니 wiki 크롤러를 한 번 제작해보려했다.
마드리드 거리를 구역 카테고리로 나눈 위키 페이지를 목표로 했다.
각 구역의 모든 거리의 이름과 내용을 모두 긁어오려 한다.

class WikicrawlerSpider(scrapy.Spider):
name = 'wikicrawler'
def start_requests(self):
yield scrapy.Request(url='https://es.wikipedia.org/wiki/Categor%C3%ADa:Calles_del_distrito_Centro', callback=self.parse_barrio)
def parse_barrio(self, response):
barrio_links1 = response.css('div.mw-content-ltr')[0]
barrio_links2 = barrio_links1.css('div.CategoryTreeItem a::attr(href)').getall()
barrio_names = barrio_links1.css('div.CategoryTreeItem a::text').getall()
for index, barrio_link in enumerate(barrio_links2):
yield scrapy.Request(url='https://es.wikipedia.org'+barrio_link, callback=self.parse_calleList, meta={'barrio_name':barrio_names[index]})
def parse_calleList(self,response):
calle_links1 = response.css('div.mw-content-ltr')[0]
calle_links2 = calle_links1.css('div.mw-category-group a::attr(href)').getall()
calle_names = calle_links1.css('div.mw-category-group a::text').getall()
for index, calle_link in enumerate(calle_links2):
yield scrapy.Request(url='https://es.wikipedia.org'+calle_link, callback=self.parse_calle, meta={'barrio_name':response.meta['barrio_name'], 'calle_name':calle_names[index]})
def parse_calle(self, response):
title = response.meta['calle_name']
content = response.css('div.mw-parser-out > p')흐름은
1. start_request에서 request객체를 parse_barrio함수에 yield로 넘긴다.
2. parse_barrio에서 각 구역의 링크와 이름을 따서 parse_calleList로 넘긴다.
3. parse_calleList에서 각 거리 이름과 링크를 parse_calle에 넘긴다.
4. parse_calle에서 title과 content를 짠다.
문제는 !
scrapy의 response.css 셀렉터로 wiki 페이지의 바디 콘텐츠 텍스트를 따려는데 위키의 html 구성이 이상하다. 텍스트가 들어있는 div.mw-parser-output 의 하위 태그인 p를 찝으면 sup/ span/ li등 너무 많은 것들이 뒤따라온다.
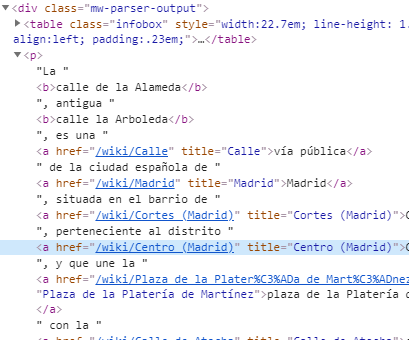

분명 BeautifulSoup 으로 했을 때는 간편하게 뽑힌 것 같은데 왜 안될까... 계속 요리조래 시도해봤으나 p 태그만 지정하면 a태그의 링크가 걸려있는 인물/지형 고유명사들이 다 날라가버리고 p를 지정하지 않으면 수많은 잡태그들을 다가져와야한다. 열심히 고민해서 내린 결론은 ... BeautifulSoup을 쓰자는 것이다. ㅎ_ㅎ
scrapy가 무슨 parser를 쓰는지 모르겠으나 BeautifulSoup으로 잘 되던것이 안되니까, 내가 뭐 엄청난 코딩 능력자도 아니고 시간도 부족한데 여기에 시간을 뺏길 순 없으니까 그냥 뷰티풀숲으로 해결하니 바로 스엉공
def parse_calle(self, response):
barrio = response.meta['barrio_name']
title = response.meta['calle_name']
soup = BeautifulSoup(response.text, 'lxml')
#div 바로 밑에 p
body = soup.select('div.mw-parser-output > p')
#contents에 reference는 빼기 위해 [:-1]
body = [i.get_text() for i in body[:-1]]
content = ' '.join(body)
dataset = WikiItem()
dataset['barrio'] = barrio
dataset['title'] = title
dataset['content'] = content
yield dataset* 리스트 내의 문자열을 합치려면 ' '.join(list)
매우 - 성공적.
나중에 scrapy parser lxml로 구글링해보니

scrapy 공식 doc에서도 lxml쓰고 싶으면 beatifulsoup 쓰라하니 결론적으로는 내가 한 방법이 맞았다 ㅋㅋ
__
다음 목표는 TF-IDF로 각 콘텐츠의 주요 키워드를 뽑느 것이다. 물론 TF-IDF를 하려면 선행지식이 많---이 필요하지만 나는 그냥 바로 울며 겨자먹기로 바로 머리부터 들이대려 한다. 어떻게 될련지, 성공한지는 다음 포스트에서 !
'코드' 카테고리의 다른 글
| [html, css]티스토리 블로그 스킨 편집하기 _ font (0) | 2020.03.12 |
|---|---|
| 알고리즘따위 1도 모르는 코딩초보자, TextRank에 TF-IDF적용 분투기 (0) | 2019.11.04 |
| [PYTHON/SCRAPY] scrapy 크롤러 파싱 오류(dont_filter) (0) | 2019.10.29 |
| [python, MySQL] from 파이썬 크롤러 to MySQL via pymysql (0) | 2019.10.17 |
| [python] gmarket 크롤러 중에 마주친 오류 (0) | 2019.10.16 |
- Total
- Today
- Yesterday
- 블로그
- 이슈
- Selenium
- 유럽
- coding
- 항공
- 저널
- HTML
- 스페인
- nltk
- 분석
- python
- Crawling
- flask
- NLP
- 글쓰기
- 일기
- scrapy
- 코로나
- 유튜버
- 마드리드
- BeautifulSoup
- 오류
- error
- 유튜브
- 파이썬
- css
- DATABASE
- 리뷰
- 런업
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |