
티스토리 뷰
사건의 발단 :
친구가 경기지역화폐 어쩌구 공모전에 지원하기 위해 경기지역화폐 사이트에서 가맹점 리스트를 크롤링을 부탁함
사건의 전개 :
1. 경기지역화폐의 사이트에 들어가서 html 구조를 보니 복잡하지 않아서 1~2시간이면 내 실력에 충분히 할 수 있다고 판단.
2. 그 전날 tutorial을 따라해본 scrapy로 해보자고 결심.
2-1. scrapy shell 에서 가맹점 타이틀/카테고리/주소/번호를 따 봄
2-2. 붙어서 마구마구 코드를 짜기 시작
실제 코드가 아니라 예시입니당
for 페이지 in 페이지리스트:
html을 따고
스크래파이 리스폰스를 받고
'table tbody'로 테이블을 받고
다시 for 행 in 'table tbody'테이블리스트:
행.title
행.address
행...
2-3. 하지만 for문으로 돌리니 행에서 데이터들이 뽑히지 않는다.. 왜?
2-4. 한참 삽질을 한 후 보니 테이블이 ul/li 구조가 아니라 테이블 아래 tr/td 로 밖에 되어있지 않아 구별자가 없다!!
2-5. 따라서 크롤링을 하려 해도 행의 각 항목마다 null이 있어도 표시할 수가 없다.
3. 내가 이러려고 scrapy를 배웠나 자괴감이 들었으나 갑자기 불현듯 떠오른 google keep에 저장해둔 웹크롤링에 있어서 명심해야할 사항이 생각났다
복잡한 태그를 만나면 당장 달려들어 여러 줄의 코드를 써서라도 필요한 정보를 추출하고 싶은 생각이 들 겁니다. 하지만 이 장에서 소개하는 태크닉을 부주의하게 사용한다면 코드는 디버그하기 어려워지거나, 취약해지거나, 혹은 그 둘 다가 될 수도 있습니다.
당장 달려드기 전에:
'페이지 인쇄'같은 링크를 찾아보거나, 더 나은 HTML구조를 갖춘 모바일 버전 사이트를 찾아보십시오.
자바스크립트 파일에 숨겨진 정보를 찾으십시오. 물론 이렇게 하려면 자바스크립트 파일을 불러와서 분석해야 할 겁니다. 필자는 사이트에 포함된 구글 지도를 조작하는 자바스크립트를 살펴본 후 위도와 경도가 포함된 거리 주소를, 깔끔하게 배열로 정리된 형태로 수집했던 일이 있습니다.
중요한 정보는 페이지 타이틀에 있을 때가 대부분이지만, 원하는 정보가 페이지 URL에 들어 있을 때도 있습니다.
원하는 정보가 오직 이 웹사이트에만 있다면 할 수 있는 일이 더는 없을 수 있습니다. 그렇지 않다면, 이 정보를 다른 소스에서 가져올 수는 없는지 생각해보십시오. 다른 웹사이트에 같은 데이터가 있지는 않을까요? 이 웹사이트에 있는 데이터가 혹시 다른 웹사이트에서 수집한 것은 아닐까요?
데이터가 깊숙이 파묻혀 있거나 정형화되지 않았을수록, 곧바로 코드부터 짜서는 안됩니다. 심호흡을 하고 대안이 없는지 생각해보십시오. 대안이 없다고 확신한다면, 이 장의 내용이 도움이 될 겁니다.
_라이언 미첼, <파이썬으로 웹크롤러 만들기> 중
3-1. 다시 마음을 잡고 데이터 형을 보니 차라리 테이블 자체를 가져와버릴까 라는 생각이 듬
3-2. 예전에 모두의 데이터분석 with 파이썬에서 위키 올림픽 테이블을 그대로 가져온 사례가 생각나서 찾아보니 pandas로 한거였다
3-3. 그래서 판다스로 가져와보니...
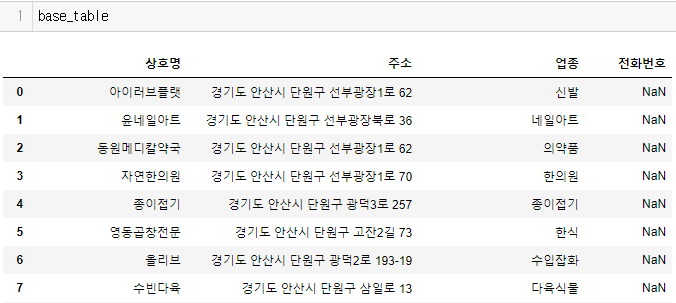
4. 결국 selenium으로 페이지 넘겨가며 판다스로 테이블따서 csv로 추출하는 것으로 해피엔딩
사후분석:
웹크롤러 제작을 배우며 단순히 기술을 익힌다고 생각하지말고 자료의 구조를 분석하고 어떻게 접근해야하는지를 공학적으로 생각하는 방법을 배워야한다. SCRAPY를 새로 배웠다고 씽나서 아무데나 갖다대면 안된다. 닭 잡는데 소 잡는 칼을 쓸 수 없는 것처럼. 물-론 고수들은 연장에 구애받지 않지만 나는 생초짜잖아...
느낀점:
프로그래밍을 배운다는 것은 단순히 언어와 기술을 익히는 것뿐만 아니라 세상을 공학적으로 바라보는 것을 의미한다. 차분히 구조와 분석을 통해서 결론을 도출하고 판단하는 것은 직관과 느낌을 따르는 것보다 재미없어 보이지만 더 안전하고, 유용하고, 정확하다(그리고 원하는 결과를 얻었을 때 더 유재미를 많이 얻을 수 있다).
부가정보:
제작을 끝내고 사진찍는 누나와 통화하며 크롤러 이야기를 하던 중 국회기록보존소라는 키워드가 튀어나왔다. 들어가보니 내가 원하는 20세기 기록들과 무려 API까지 제공하고 있었다. 상상치 못했던 뜻밖의 ALGO INIMAGINABLE한 수확이다. 매우 기부니가 좋아졌따.
오늘의 짜근 오류들 :
1. 동일형의 데이터프레임끼리 +로 합치면 동일 필드, 동일 로우로 합쳐진다. 이어붙이기는 :
pd.concat([dataframe1,dataframe2], axis=0)으로 해서 빈 데이터프레임에 결과 데이터프레임을 이어붙일 수 있다.
2. selenium으로 페이지를 넘길 때 for문 range를 10으로 줬기 때문에 중간에 더이상 페이지가 없으면 NoSuchElementException 오류가 생긴다.
2-1. 그래서 element = driver.find_element_by_link_text(커져가는숫자)로 변수를 할당한 다음 if element:로 해서 if-불리언문을 시도해봤는데 오류처리가 되지 않았다.
2-2. 그래서 try / except 로 시도를 해봤으나 다음과 같은 ㅠㅠ를 마주했다.
*NameError: name 'NoSuchElementException' is not defined
2-2. 구글링을 했더니
from selenium.common.exceptions import NoSuchElementException,StaleElementReferenceException으로 정의를 해줘야만 한단다.
*https://stackoverflow.com/questions/19200497/python-selenium-webscraping-nosuchelementexception-not-recognized
python selenium webscraping "NoSuchElementException" not recognized
Sometimes on a page I'll be looking for an element which may or may not be there. I wanted to try/catch this case with a NoSuchElementException, which selenium was throwing when certain HTML elements
stackoverflow.com
2-3. 예외처리는 어렵다는 것을 다시 한 번 깨닫고 갑니다.
3. 판다스 데이터프레임을 csv로 내보낼 때 encoding = 'cp949'를 잊지 말자원피스의 cp9이 계속 생각난다.
p.s) 판다스 공부하기 싫었는데 어제 판다스로 엑셀뽑으면서 판다스를 공부할 의욕이가 또 생겼다. 의욕아...
원래 공부는 이렇게 연결연결해서 하는건가보다.
p.s.2) 데이터베이스를 pymysql로 학습하는 강의를 듣는 중이다. 이번 주 안에 database와 pandas를 내 머릿속에 pip install로 저!장!하여 주말까지는 친구에게 간단한 데이터분석 자료라도 넘겨줘야지. (공모전에서 수상하면 돈을 나눠준다고 하였다)
'코드' 카테고리의 다른 글
| [python, MySQL] from 파이썬 크롤러 to MySQL via pymysql (0) | 2019.10.17 |
|---|---|
| [python] gmarket 크롤러 중에 마주친 오류 (0) | 2019.10.16 |
| BeautifulSoup 모듈 find와 select의 차이점 - 복잡한 웹을 간단하게 (6) | 2019.10.16 |
| [python] 크롤러 중 마주친 AttributeError 예외처리 (0) | 2019.10.14 |
| 20191006 네이버 영화 댓글 크롤러 제작 수집 오류 (0) | 2019.10.07 |
- Total
- Today
- Yesterday
- 파이썬
- Selenium
- 코로나
- 리뷰
- 분석
- 글쓰기
- 유럽
- 오류
- python
- 블로그
- DATABASE
- 이슈
- NLP
- error
- Crawling
- 항공
- scrapy
- HTML
- 유튜버
- 유튜브
- 스페인
- flask
- 런업
- 저널
- css
- nltk
- coding
- 일기
- 마드리드
- BeautifulSoup
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |